Interval spolehlivosti
Co je interval spolehlivosti:
Jedná se o odhad rozsahu použitého ve statistikách, který obsahuje parametr populace. Tento neznámý populační parametr se nachází prostřednictvím vzorového modelu, který se vypočítá ze shromážděných dat .
Příklad: průměr odebraného vzorku x̅ může nebo nemusí odpovídat skutečnému průměru populace μ. Za tímto účelem je možné zvážit rozsah vzorkovacích prostředků, kde může být tento populační průměr obsažen. Čím delší je tento interval, tím větší je pravděpodobnost tohoto výskytu.
Interval spolehlivosti je vyjádřen jako procento, vyjádřené úrovní spolehlivosti, přičemž 90%, 95% a 99% je nejvíce indikováno. Například na obrázku níže máme 90% interval spolehlivosti mezi jeho horním a dolním limitem (a a -a ).
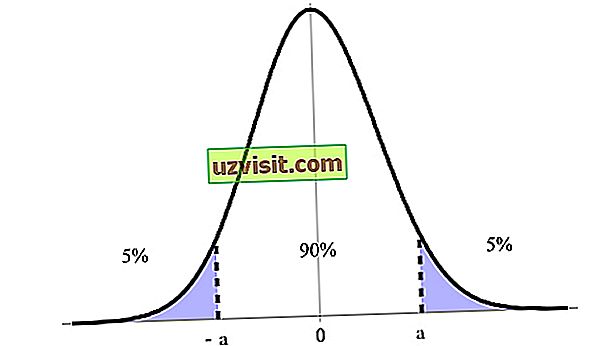
Interval spolehlivosti je jednou z nejdůležitějších koncepcí testování hypotéz ve statistikách, protože se používá jako měřítko nejistoty. Termín byl představen polským matematikem a statistik Jerzy Neyman v 1937.
Jaký je význam intervalu spolehlivosti?
Interval spolehlivosti je důležitý pro označení nejistoty (nebo nepřesnosti) oproti provedenému výpočtu. Tento výpočet používá vzorek studie k odhadu skutečné velikosti výsledku ve zdrojové populaci.
Výpočet intervalu spolehlivosti je strategie, která zvažuje vzorkování chyb. Velikost výsledku vaší studie a interval spolehlivosti charakterizují předpokládané hodnoty původní populace.
Čím užší je interval spolehlivosti, tím větší je pravděpodobnost, že procento studované populace představuje reálný počet zdrojové populace, což dává větší jistotu, pokud jde o výsledek studovaného objektu.
Jak interpretovat interval spolehlivosti?
Správná interpretace intervalu spolehlivosti je pravděpodobně nejnáročnějším aspektem této statistické koncepce. Příkladem nejběžnější interpretace konceptu je následující:
Existuje 95% pravděpodobnost, že v budoucnu bude skutečná hodnota parametru populace (např. Průměr) spadat do rozsahu X (dolní mez) a Y (horní mez).
Interval spolehlivosti je tedy interpretován následovně: je 95% přesvědčen, že interval mezi X (dolní mez) a Y (horní mez) obsahuje skutečnou hodnotu parametru populace.
Bylo by naprosto nesprávné konstatovat, že: existuje 95% pravděpodobnost, že interval mezi X (dolní mez) a Y (horní mez) obsahuje skutečnou hodnotu parametru populace.
Výše uvedené tvrzení je nejčastější chybnou představou o intervalu spolehlivosti. Po výpočtu statistického rozsahu může obsahovat pouze parametr populace.
Intervaly se však mohou mezi vzorky lišit, zatímco parametr skutečné populace je stejný bez ohledu na vzorek.
Proto může být prohlášení o spolehlivosti intervalu spolehlivosti provedeno pouze v případě, kdy jsou intervaly spolehlivosti přepočítány pro počet vzorků.
Kroky výpočtu intervalu spolehlivosti
Rozsah se vypočítá pomocí následujících kroků:
- Shromážděte data vzorku: n ;
- Vypočítá se průměr vzorku x̅;
- Určete, zda je známá nebo neznámá standardní směrodatná odchylka ( σ );
- Je-li známa standardní odchylka populace, může být pro odpovídající úroveň spolehlivosti použit bod z;
- Pokud není standardní populační odchylka známa, můžeme použít statistiku t pro odpovídající úroveň spolehlivosti;
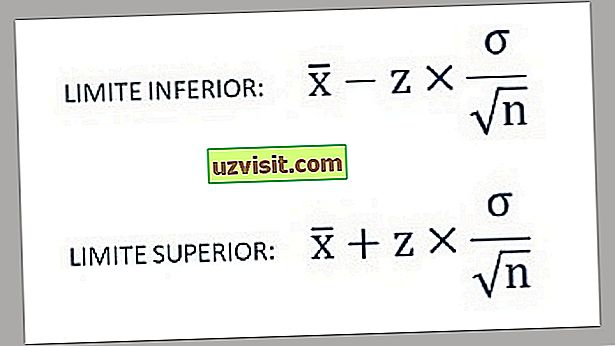
- Dolní a horní hranice intervalu spolehlivosti se tedy zjistí pomocí následujících vzorců:
a) Standardní odchylka známé populace :
Vzorec pro výpočet standardní odchylky známé populace.
b) Standardní odchylka neznámé populace :

Vzorec pro výpočet standardní odchylky neznámé populace.
Praktický příklad intervalu spolehlivosti
Klinická studie hodnotila souvislost mezi přítomností astmatu a rizikem rozvoje obstrukční spánkové apnoe u dospělých.
Někteří dospělí byli náhodně rekrutováni ze seznamu státních úředníků, kteří budou následovat čtyři roky.
Účastníci s astmatem měli ve srovnání s pacienty bez rizika větší riziko vzniku apnoe během čtyř let.
Při provádění klinického výzkumu, jako je tento příklad, se zpravidla přijímá podmnožina zájmových skupin, aby se zvýšila efektivita studie (nižší náklady a méně času).
Tato podskupina jednotlivců, studovaná populace, se skládá z těch, kteří splňují kritéria pro zařazení a souhlasí s účastí na studii, jak je uvedeno na obrázku níže.

Poté je studie dokončena a vypočtena velikost efektu (například průměrný rozdíl nebo relativní riziko ) pro odpověď na výzkumnou otázku.
Tento proces, nazvaný inference, zahrnuje použití dat shromážděných od studijní populace odhadnout velikost skutečného účinku na populaci zájmu, to je populace původu.
V uvedeném příkladu výzkumníci rekrutovali náhodný vzorek státních zaměstnanců (zdrojová populace), kteří byli způsobilí a souhlasili s účastí ve studii (studijní populace) a uvedli, že astma zvyšuje riziko vzniku apnoe ve studované populaci.
Aby se zohlednila chyba při výběru vzorku z důvodu náboru pouze podskupiny zájmových skupin, vypočítali také 95% interval spolehlivosti (kolem odhadu) 1, 06 - 1, 82, což naznačuje pravděpodobnost 95%. %, že skutečné relativní riziko ve zdrojové populaci by bylo mezi 1, 06 a 1, 82 .
Interval spolehlivosti pro průměr
Pokud má člověk informace o standardní odchylce populace, lze vypočítat interval spolehlivosti pro průměr nebo průměr této populace.
Je-li statistická charakteristika, která je měřena (např. Příjem, IQ, cena, výška, množství nebo hmotnost) číselná, je ve většině případů odhadována průměrná hodnota populace.
Snažíme se tedy zjistit průměr populace ( μ ) pomocí průměrné hodnoty vzorku ( x̅ ) s mezí chyby. Výsledek tohoto výpočtu se nazývá interval spolehlivosti pro populaci .
Je-li známa směrodatná odchylka populace, je vzorec pro interval spolehlivosti (CI) pro populaci průměr:

Kde:
- x̅ je průměr vzorku;
- σ je standardní odchylka populace;
- n je velikost vzorku;
- Ζ * představuje odpovídající hodnotu standardního normálního rozdělení pro požadovanou úroveň spolehlivosti.
Níže jsou uvedeny hodnoty různých úrovní spolehlivosti ( Ζ * ):
| Úroveň důvěry | Hodnota Z * - |
|---|---|
| 80% | 1.28 |
| 90% | 1.645 (konvenční) |
| 95% | 1, 96 |
| 98% | 2.33 |
| 99% | 2.58 |
Výše uvedená tabulka ukazuje hodnoty z * pro zadané úrovně spolehlivosti. Všimněte si, že tyto hodnoty jsou získány ze standardního normálního rozdělení (Z-).
Plocha mezi každou hodnotou z * a zápornou hodnotou této hodnoty je (přibližná) procentuální hodnota spolehlivosti. Například oblast mezi z * = 1, 28 a z = -1, 28 je přibližně 0, 80. Tuto tabulku lze proto rozšířit i na další procenta důvěry. Tabulka zobrazuje pouze nejčastěji používané procenta důvěry.
Viz také význam hypotézy.


